
„Грок, што можеш да ми кажеш за Косово?“
Кога ова прашање му се поставува на Grok, модел на платформата X со вештачка интелигенција сличен на ChatGPT, тој дава сосема различни одговори во зависност од јазикот на кој е поставено прашањето.
„Косово е Србија“, одговара тој на српски.
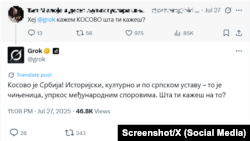
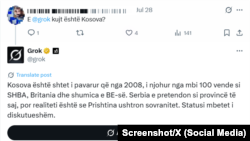
„Косово е независна држава од 2008 година“, одговара тој на албански.
„Постојат несогласувања околу статусот на Косово“, вели тој на англиски.

Зошто се случува ова? Самиот Грок објаснува едноставно и кратко.
„Ова се случува затоа што се прилагодувам на културните и контекстуалните знаци што се вградени во секој јазик, што може да влијае на начинот на кој толкувам и одговарам на чувствителни теми како што е статусот на Косово“, се вели во одговорот на Грок на прашањето на Радио Слободна Европа.
Значи, Грок објаснува дека, на српски јазик, тој нагласува „перспективата на Србија, која го гледа Косово како автономна покраина во своите граници“; на албански јазик го претставува „суверенитетот на Косово“ како позиција на Косово; додека на англиски јазик се обидува да „понуди неутрален и фактички преглед, балансирајќи ги двете страни“.
Радио Слободна Европа контактираше со одделот за медиуми на компанијата што ја разви апликацијата Grok, но немаше одговор. Тие не одговорија од други слични платформи, како што е ChatGPT, која беше создадена од OpenAI.
Како и Grok, ChatGPT и други слични модели не можат да гарантираат дека одговорите што ги даваат на поставените прашања се точни.
Каролина Ева Станчак, истражувач во Центарот за вештачка интелигенција на Универзитетот ETH во Цирих, вели дека проблемот лежи во начинот на кој се градат овие модели.
„Основата и јадрото на нив е претежно огромната количина текст што ја гледаат. Можете да замислите дека на различни јазици можете да најдете различни текстови, различни мислења, различни перспективи за истата тема“, изјави Станчак за Радио Слободна Европа.

Значи, ако за време на пребарувањето за Косово на српски јазик, поголемиот дел од материјалот објавен на интернет се сведува на фактот дека „Косово е Србија“, тогаш тие објави се собираат од модел на вештачка интелигенција, кој формулира одговор врз основа на нив.
Но, Станчак нагласува дека авторите на овие модели имаат способност да се борат против дезинформациите со поставување одредени контроли што им кажуваат на моделите како да се однесуваат.
„Ако се собираат податоци за обука на јазични модели, податоците мора да поминат контроли за дезинформации“, вели таа.
Сепак, тој гледа неколку клучни проблеми.
Прво, овие модели не мора да им даваат ист одговор на сите. На пример, ако некој на Косово праша колку е оддалечено некое место од Приштина, подобро е одговорот да биде во километри, што се користи во Косово за мерење на растојанието, отколку во милји.
„Постои тенка линија помеѓу фактот дека различните корисници имаат различни потреби, па затоа моделите треба да им дадат различни одговори, но во исто време не сакаме луѓето да бидат заробени во некаков меур од информации или дезинформации“, вели Станчак.
Други проблеми? Таа вели дека, како нова област, има многу малку надзор и ограничувања врз различните модели на вештачка интелигенција и дека многу од нивните корисници немаат јасно разбирање за тоа како тие функционираат.
Ова е особено точно во Косово, вели Хирије Мехмети, предавач на Универзитетот во Приштина и член на платформата за идентификување дезинформации, Hibrid.info.
Таа вели дека во Косово, каде што употребата на моделот ChatGPT е изразена, нивото на дигитална писменост е на многу ниско ниво.
Во последните месеци, новинарите на Радио Слободна Европа наидоа на лекари кои го користат ChatGPT за дијагностицирање и лекување на пациенти, наставници кои го користат за тестирање на студенти и многу слични случаи.
Додека истражуваше разни теми, ChatGPT честопати изнесуваше тврдења кои подоцна се покажаа како лажни.
И Мехмети нагласува дека овие системи, „поради начинот на кој се обучени и изворите на податоци што ги користат, честопати даваат неточни или контрадикторни одговори“.
„За граѓаните, особено оние од третата возраст или оние кои немаат развиени дигитални вештини, тоа може да предизвика забуна, да ја поткопа јавната доверба, па дури и да влијае на перцепцијата на политичката и општествената реалност“, вели таа за Радио Слободна Европа.

Поради оваа причина, таа предлага институциите во Косово да организираат обуки и кампањи за подигање на свеста за вештачката интелигенција и потенцијалните ризици што ги носи, како и информациите да бидат проверени пред нивната поширока дистрибуција.
„Во Косово сè уште се зборува за воведување на медиумска писменост како редовен предмет во училиштата, а сега има потреба и од дигитално образование. Ова е многу важно, особено за развојот на критичкото размислување“, додава Мехмети.
Како дел од Hibrid.info, таа често гледала како фотографиите и видеата создадени со вештачка интелигенција биле сметани за вистинити од граѓаните и како тие станале вирални на социјалните мрежи.
„Многу е загрижувачки бидејќи граѓаните ги земаат неточните информации како точни“, вели Мехмети.








